[TOC]
Bigcache 的特点:
并发支持,快速, 过期大量条目而不影响性能.
bigcache将 缓存条目放在了堆上,节省了GC. 为了实现这一点. 需要对字节切片进行操作. 因此涉及到缓存条目的序列化与反序列化.
bigcache, freecache 和 map 的基准测试
内存使用情况
可能会遇到,系统内存指数增长. 属于预期内行为. Go 运行时 以 跨度(span)为单位分配内存,并在不需要他们是将状态修改为 free 来通知操作系统.在操作系统需要重新调整地址用途之前. 跨度将保留为进程资源的一部分.
怎么做到的高性能?
BigCache依赖于 go1.5中做出的优化.issue9477: 对于key value 中没有指针的map,GC将忽略其内容.因此 bigCache 中使用 map[uint64]uint32, key 为 hash(key). value 是 item的 偏移量.
item 保存在字节切片中,目的是为了 再次忽略 GC. 字节切片大小可以增长到 MB 而不影响性能, 因为 GC只能看到指向他们的 单个 指针.
如何解决 hash 冲突(Hash Collisions)?
Bigcache 不解决 hash 冲突. 当一个新的item 与老 item hash(key)相同. 新 item 会覆盖老item.
Bigcache Vs freecche
两种缓存都提供了相同的功能. 但是他们是以不同的方式 减少 GC开销. bigCache 一依赖 map[uint64]uint32, freecache 实现了自己的基于切片的映射 来减少指针数量.
Bigcache 相对于 freecache 的优势之一是: 不需要提前知道 缓存大小,因为 Bigcache 已满时,可以为新item 重新分配额外的内存. 而不是像 freecache 那样覆盖现有的.但是 Bigcache 也提供了参数 HardMaxCacheSize 设置缓存最大大小.
源码解析
1. 一些概念
1. shard
分片, 用于 减少锁粒度 ,增加并发度. cache 默认 有 1024 个分片. (需要时 2^n, 快速进行 hash计算)
shards 初始化以后是 不可以扩容的.
2. CleanWindow
删除过期entry 的 时间间隔(interval).
默认配置为 1s. 如果设置为 < 1s, 可能会适得其反.
3. lifeWindow
entry 的过期时间.
bigcache 的一个feature: 不支持为 特定的entry 单独设置 过期时间.
2. 数据结构

1. cache
// BigCache is fast, concurrent, evicting cache created to keep big number of entries without impact on performance.
// It keeps entries on heap but omits GC for them. To achieve that, operations take place on byte arrays,
// therefore entries (de)serialization in front of the cache will be needed in most use cases.
type BigCache struct {
shards []*cacheShard // shard分片 减小锁粒度,长度为 2^N
lifeWindow uint64
clock clock // 时钟,计算过期时间 会用到
hash Hasher // hash 算法 分 shard
config Config
shardMask uint64 // 2^N-1
close chan struct{}
}
2. shard
type cacheShard struct {
hashmap map[uint64]uint32 //存储索引 key: hashKey value: value存入 byteQueue的 offset
entries queue.BytesQueue // 存储实际的数据 的 环形字节数组
lock sync.RWMutex // 锁
entryBuffer []byte //
onRemove onRemoveCallback // 回调函数, 有多种实现方式
isVerbose bool
statsEnabled bool
logger Logger
clock clock
lifeWindow uint64
hashmapStats map[uint64]uint32 // 记录 key的 requestCount
stats Stats // shard 的 缓存 统计状态
cleanEnabled bool // 是否开启 清理
}
3. entry
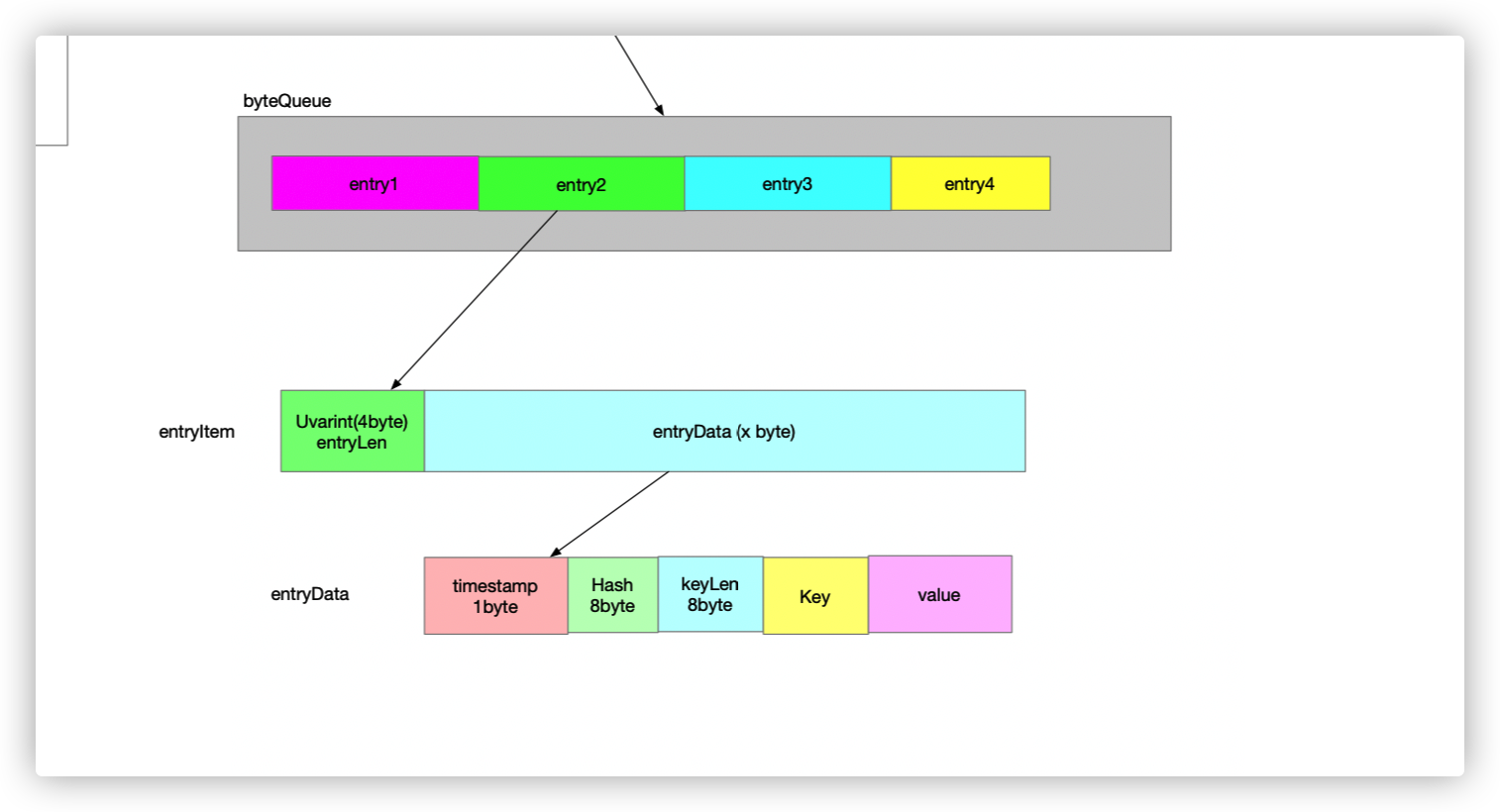
// EntryInfo holds informations about entry in the cache
type EntryInfo struct {
timestamp uint64
hash uint64
key string
value []byte
err error
}timestamp: 8byte.
Hash: 8byte.
keyLen: 2byte.
key: Nbyte.
value: Nbyte.
// headerSize(timestamp + hash + keyLen) = 18byte
将 kv 包装成 entry.
// header | kv
// timestamp|hash|keySize|key|value
func wrapEntry(timestamp uint64, hash uint64, key string, entry []byte, buffer *[]byte) []byte {
keyLength := len(key)
blobLength := len(entry) + headersSizeInBytes + keyLength
// 如果 blob 长度 > buffer,重新申请一个 buffer
if blobLength > len(*buffer) {
*buffer = make([]byte, blobLength)
}
blob := *buffer
binary.LittleEndian.PutUint64(blob, timestamp)
binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash)
binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength))
copy(blob[headersSizeInBytes:], key)
copy(blob[headersSizeInBytes+keyLength:], entry)
return blob[:blobLength]
}解析 entry 为 kv 结构:
// 读取 value: array[headersSizeInBytes + keyLen:]
func readEntry(data []byte) []byte {
// 读取 keyLen
length := binary.LittleEndian.Uint16(data[timestampSizeInBytes+hashSizeInBytes:])
// copy on read
dst := make([]byte, len(data)-int(headersSizeInBytes+length))
copy(dst, data[headersSizeInBytes+length:])
return dst
}
// 读取 timestamp: uint64(array)
func readTimestampFromEntry(data []byte) uint64 {
return binary.LittleEndian.Uint64(data)
}
// 读取 key: array[headerSize:headerSize + keyLen]
func readKeyFromEntry(data []byte) string {
length := binary.LittleEndian.Uint16(data[timestampSizeInBytes+hashSizeInBytes:])
// copy on read
dst := make([]byte, length)
copy(dst, data[headersSizeInBytes:headersSizeInBytes+length])
return bytesToString(dst)
}
// compare key and entry.
func compareKeyFromEntry(data []byte, key string) bool {
length := binary.LittleEndian.Uint16(data[timestampSizeInBytes+hashSizeInBytes:])
return bytesToString(data[headersSizeInBytes:headersSizeInBytes+length]) == key
}
// 读取 hash: uint64(array[timestampSizeinByte:])
func readHashFromEntry(data []byte) uint64 {
return binary.LittleEndian.Uint64(data[timestampSizeInBytes:])
}4. byteQueue
实际存储数据.
type BytesQueue struct {
full bool
array []byte
capacity int
maxCapacity int
head int
tail int
count int
rightMargin int
headerBuffer []byte
verbose bool
}一个 kv 结构 是一个 entry. entry 存储在 array 里面. 通过 offset 来进行访问.
3. 常用方法
3.1 缓存初始化
// NewBigCache initialize new instance of BigCache
func NewBigCache(config Config) (*BigCache, error) {
return newBigCache(config, &systemClock{})
}
func newBigCache(config Config, clock clock) (*BigCache, error) {
// param check
if config.Hasher == nil {
config.Hasher = newDefaultHasher()
}
cache := &BigCache{
shards: make([]*cacheShard, config.Shards),
lifeWindow: uint64(config.LifeWindow.Seconds()),
clock: clock,
hash: config.Hasher,
config: config,
shardMask: uint64(config.Shards - 1), // 用于 快速计算 hash 值
close: make(chan struct{}), // 接收 close 信号的 一个 chan, 关闭主动清理任务
}
// 设置 onremove 回调函数
var onRemove func(wrappedEntry []byte, reason RemoveReason)
if config.OnRemoveWithMetadata != nil {
onRemove = cache.providedOnRemoveWithMetadata
} else if config.OnRemove != nil {
onRemove = cache.providedOnRemove
} else if config.OnRemoveWithReason != nil {
onRemove = cache.providedOnRemoveWithReason
} else {
onRemove = cache.notProvidedOnRemove
}
// 逐个初始化 shard
for i := 0; i < config.Shards; i++ {
cache.shards[i] = initNewShard(config, onRemove, clock)
}
// 主动清理 过期数据
if config.CleanWindow > 0 {
go func() {
ticker := time.NewTicker(config.CleanWindow)
defer ticker.Stop()
for {
select {
case t := <-ticker.C:
cache.cleanUp(uint64(t.Unix())) // 进行过期数据清理
case <-cache.close:
return
}
}
}()
}
return cache, nil
}3.2 Get
// Get reads entry for the key.
// It returns an ErrEntryNotFound when
// no entry exists for the given key.
func (c *BigCache) Get(key string) ([]byte, error) {
hashedKey := c.hash.Sum64(key)
shard := c.getShard(hashedKey) // 取余操作, c.shards[hashedKey&c.shardMask]
return shard.get(key, hashedKey) // 调用 shard.get 获取 value
}bigcache.hash 默认使用 fnv hash算法. new 64-bit FNV-1a Hasher 算法 可以 0 内存申请.
shard.Get
func (s *cacheShard) get(key string, hashedKey uint64) ([]byte, error) {
// 加 读锁, 保护 hashmap
s.lock.RLock()
wrappedEntry, err := s.getWrappedEntry(hashedKey)
if err != nil {
s.lock.RUnlock()
return nil, err
}
// 判断 key 是否相同. 当发生hash冲突时,如果 key不相同, 直接返回 ErrEntryNotFound
// bigcache 不解决 hash Collision
if entryKey := readKeyFromEntry(wrappedEntry); key != entryKey {
s.lock.RUnlock()
s.collision()
if s.isVerbose {
s.logger.Printf("Collision detected. Both %q and %q have the same hash %x", key, entryKey, hashedKey)
}
// 如果 key 不存在, 返回 `ErrEntryNotFound`
return nil, ErrEntryNotFound
}
// entry: value的 字节数组
entry := readEntry(wrappedEntry)
s.lock.RUnlock()
s.hit(hashedKey)
return entry, nil
}3.3 Set
// Set saves entry under the key
func (c *BigCache) Set(key string, entry []byte) error {
hashedKey := c.hash.Sum64(key) // 计算 hash 值
shard := c.getShard(hashedKey) // 根据 取余 计算 分片
return shard.set(key, hashedKey, entry) //
}
shard :
func (s *cacheShard) set(key string, hashedKey uint64, entry []byte) error {
currentTimestamp := uint64(s.clock.Epoch())
s.lock.Lock()
// hash Collision| key 已存在(并未进行更新), 将原来的 entry 软删除
if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 {
if previousEntry, err := s.entries.Get(int(previousIndex)); err == nil {
resetKeyFromEntry(previousEntry)
//remove hashkey
delete(s.hashmap, hashedKey)
}
}
// 如果 未开启 定时 清理任务, 那么 主动调用, 将最早的数据 清理(如果过期)
if !s.cleanEnabled {
if oldestEntry, err := s.entries.Peek(); err == nil {
s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry)
}
}
// 将kv 封装成 entry. ( 从这个方法里面可以 看出 entry 的 数据结构.)
w := wrapEntry(currentTimestamp, hashedKey, key, entry, &s.entryBuffer)
// 循环目的是为了 保证 一定放入 数据成功.
for {
// 放入 entrys 中 (bytesQueue)
if index, err := s.entries.Push(w); err == nil { // Push() 也可以看一下
s.hashmap[hashedKey] = uint32(index)
s.lock.Unlock()
return nil
}
// 如果 放入 失败, (空间不足, 那么 就用 LRU算法, 清理出空间)
if s.removeOldestEntry(NoSpace) != nil {
s.lock.Unlock()
return fmt.Errorf("entry is bigger than max shard size")
}
}
}
bigcache为何不提供更新的操作? 其实这是显而易见的:每次插入元素, bigCache 会根据插入的 key 和 value 在 BytesQueue 中申请一个固定大小的空间. 因为无法保证更新的 value 值和旧的 value 长度相同(这也是数据定长存储的劣势),这样对 bigcache > 来说,按照时间顺序的
head和tail索引值会乱掉,所以干脆就不提供更新接口了.
wrapEntry
// header | kv
// timestamp|hash|keySize|key|value
func wrapEntry(timestamp uint64, hash uint64, key string, entry []byte, buffer *[]byte) []byte {
keyLength := len(key)
blobLength := len(entry) + headersSizeInBytes + keyLength
// 如果 blob 长度 > buffer,重新申请一个 buffer
if blobLength > len(*buffer) {
*buffer = make([]byte, blobLength)
}
blob := *buffer
binary.LittleEndian.PutUint64(blob, timestamp)
binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash)
binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength))
copy(blob[headersSizeInBytes:], key)
copy(blob[headersSizeInBytes+keyLength:], entry)
return blob[:blobLength]
}3.4 Delete
// Delete removes the key
func (c *BigCache) Delete(key string) error {
hashedKey := c.hash.Sum64(key)
shard := c.getShard(hashedKey)
return shard.del(hashedKey)
}
shard.del()
// Optimistic 乐观锁机制
// 主动删除, 将 entry 中 hash值 置为 0, 如果 不存在,直接返回, 不用加写锁
func (s *cacheShard) del(hashedKey uint64) error {
// Optimistic pre-check using only readlock
s.lock.RLock()
{
itemIndex := s.hashmap[hashedKey]
if itemIndex == 0 {
s.lock.RUnlock()
s.delmiss()
return ErrEntryNotFound
}
if err := s.entries.CheckGet(int(itemIndex)); err != nil {
s.lock.RUnlock()
s.delmiss()
return err
}
}
s.lock.RUnlock()
s.lock.Lock()
{
// After obtaining the writelock, we need to read the same again,
// since the data delivered earlier may be stale now
itemIndex := s.hashmap[hashedKey]
if itemIndex == 0 {
s.lock.Unlock()
s.delmiss()
return ErrEntryNotFound
}
wrappedEntry, err := s.entries.Get(int(itemIndex))
if err != nil {
s.lock.Unlock()
s.delmiss()
return err
}
delete(s.hashmap, hashedKey)
s.onRemove(wrappedEntry, Deleted)
if s.statsEnabled {
delete(s.hashmapStats, hashedKey)
}
// 将 entry 中的 hash值 置为0,表示删除. (并不是立即回收空间)
resetKeyFromEntry(wrappedEntry)
}
s.lock.Unlock()
s.delhit()
return nil
}
4. BytesQueue
BytesQueue 是一个循环数组, 存储 entry 数据. 通过 offset 来进行访问. 减少 GC 开销. (shard 中的 hashmap 存储的是 hash(key) 与 offset 的映射关系).
bytesQueue 的几个特点:
- 存储的 entry 不会是 截断的. (一部分数据在tail, 一部分数据在 头部.)
- entry 的数据格式: 如上图所示.
// go doc queue BytesQueue
package queue // import "github.com/allegro/bigcache/v3/queue"
type BytesQueue struct {
// Has unexported fields.
}
BytesQueue is a non-thread safe queue type of fifo based on bytes array. For
every push operation index of entry is returned. It can be used to read the
entry later
func NewBytesQueue(capacity int, maxCapacity int, verbose bool) *BytesQueue
func (q *BytesQueue) Capacity() int
func (q *BytesQueue) CheckGet(index int) error
func (q *BytesQueue) Get(index int) ([]byte, error)
func (q *BytesQueue) Len() int
func (q *BytesQueue) Peek() ([]byte, error)
func (q *BytesQueue) Pop() ([]byte, error)
func (q *BytesQueue) Push(data []byte) (int, error)
func (q *BytesQueue) Reset()bigcache 的缺点 和使用中要注意的点:
- bigcache 不支持 为单个key 设置 过期时间, bigcache 中所有的 key 的过期时间是一样的. (如果有需求自己开发)
- bigcache set key 时 不会 更新 entry, 而是将原来的 entry 软删除, 在append 一个entry.
- 无持久化功能, 只能用作单机缓存
- BytesQueue 的扩容操作可能会影响性能
[参考]
Writing a very fast cache service with millions of entries in Go
Golang 高性能 LocalCache:BigCache 设计与分析
Golang 中map与GC“纠缠不清”的关系
源码