特性:
- 快速, 高性能, 多 CPU上 可扩展
- 线程安全. 多个 goroutine 可以同时读写一个cache 实例
- fastcache 设计为 在存储大量的 entry 的场景下 GC free
- fastcache 当 缓存数量达到阈值时 可以自动 清理 old entry
- 简单的API
- 简单的源代码
- cacheData 可以 保存到文件(从文件中加载)
- 在 Google App Engine 上工作
fastcache 的一些概念
bucket: 分桶, 默认 cache中有 512个 bucket, 减少锁粒度 (bucket 内部 会维护 lock, hashmap, chunk, stat(统计信息))
chunks: [][]byte 用于 存储 kv 的 一个 ringbuffer. 这里二维数组 用来模拟 循环 数组.(减少扩容操作.)

数据结构
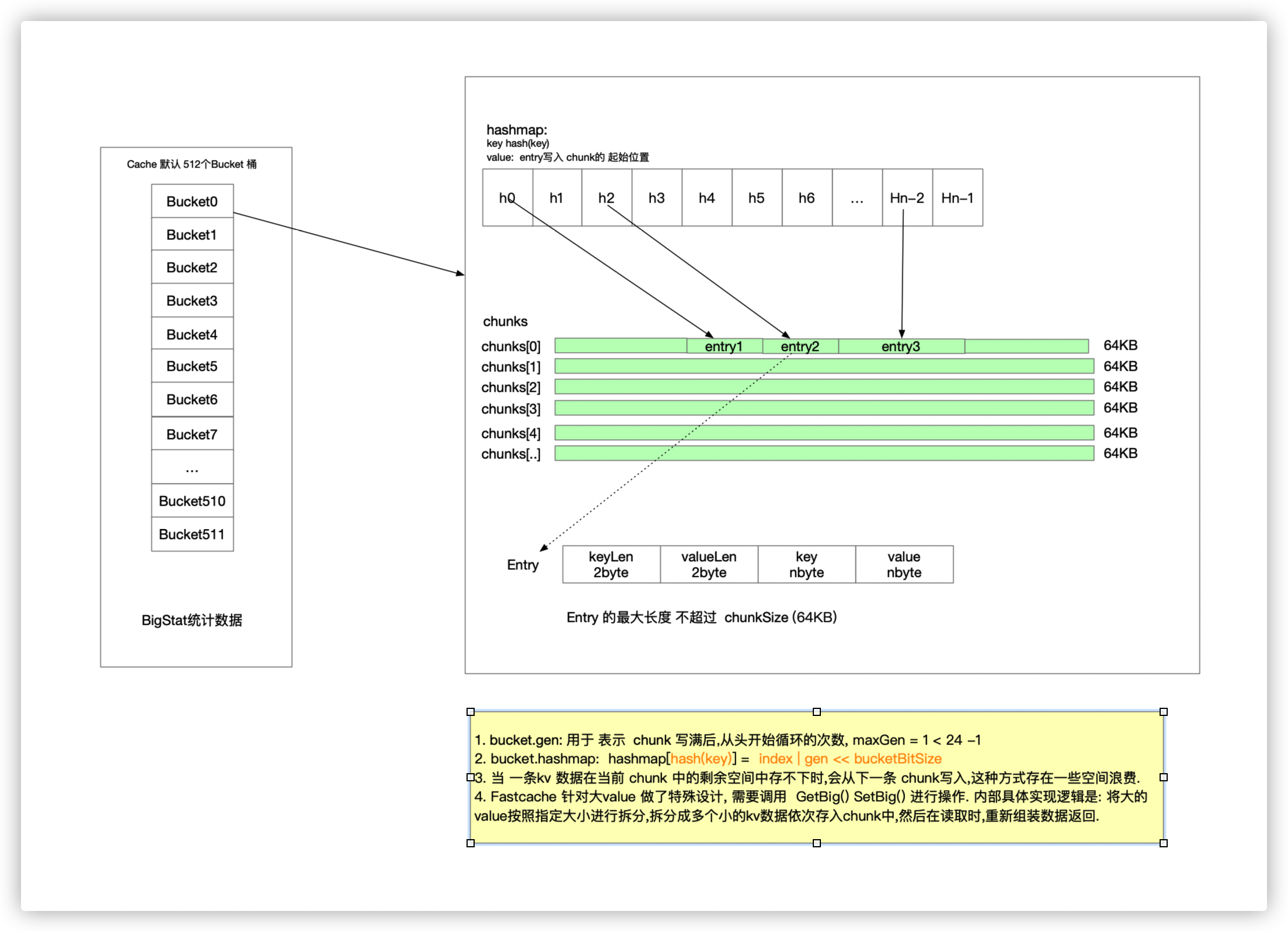
fastcache 代码比较简单.
// Cache is a fast thread-safe inmemory cache optimized for big number
// of entries.
//
// It has much lower impact on GC comparing to a simple `map[string][]byte`.
//
// Use New or LoadFromFile* for creating new cache instance.
// Concurrent goroutines may call any Cache methods on the same cache instance.
//
// Call Reset when the cache is no longer needed. This reclaims the allocated
// memory.
type Cache struct {
buckets [bucketsCount]bucket // bucketCount default 512
bigStats BigStats
}
// 一个 bucket
type bucket struct {
mu sync.RWMutex
// chunks is a ring buffer with encoded (k, v) pairs.
// It consists of 64KB chunks.
// 每个 块是64K, 也就是 chunkSize
chunks [][]byte
// m maps hash(k) to idx of (k, v) pair in chunks.
// key: hash(key) value: idx, value 在 chunk中的偏移量(byte) gen+idx
m map[uint64]uint64
// idx points to chunks for writing the next (k, v) pair.
// 用于计算下一个chunk
idx uint64 // 下一次 要写入的 位置
// gen is the generation of chunks.
gen uint64 // chunk 的循环次数
// 一些统计信息
getCalls uint64
setCalls uint64
misses uint64
collisions uint64
corruptions uint64
}
常用操作
1. New
// New returns new cache with the given maxBytes capacity in bytes.
//
// maxBytes must be smaller than the available RAM size for the app,
// since the cache holds data in memory.
//
// If maxBytes is less than 32MB, then the minimum cache capacity is 32MB. - 每个 bucket 最小 64K(一个chunk)
func New(maxBytes int) *Cache {
// param check
var c Cache
// 如果 maxByte / bucketCount 有余数的话, 把超出的部分 分填到 每个 bucket
maxBucketBytes := uint64((maxBytes + bucketsCount - 1) / bucketsCount)
for i := range c.buckets[:] {
c.buckets[i].Init(maxBucketBytes)
}
return &c
}
// bucket 初始化
func (b *bucket) Init(maxBytes uint64) {
// param check ...
// 同样的, 将多余的 字节分散到 每个 chunk
maxChunks := (maxBytes + chunkSize - 1) / chunkSize
b.chunks = make([][]byte, maxChunks)
b.m = make(map[uint64]uint64)
b.Reset()
}
2. Set
// Set stores (k, v) in the cache.
//
// Get must be used for reading the stored entry.
//
// 当 发生 overflow 或者 不太可能的 hash Collision 时, entry 将会被丢弃
// - 如果 经常发生 entry丢失, 那么应该 调用 New(), 调大 最大字节数
//
// 超过64KB(chunkSize) 不能用 Set 进行存储,应该调用 SetBig.
//
// k and v contents may be modified after returning from Set.
func (c *Cache) Set(k, v []byte) {
h := xxhash.Sum64(k)
idx := h % bucketsCount // 这里 可以 使用 位运算: h & (bucketsCount - 1)
c.buckets[idx].Set(k, v, h)
}bucket.Set()
// 2byte | 2byte | nbyte | nbyte
// keylen|valLen|key|value
func (b *bucket) Set(k, v []byte, h uint64) {
atomic.AddUint64(&b.setCalls, 1)
if len(k) >= (1<<16) || len(v) >= (1<<16) {
// Too big key or value - its length cannot be encoded
// with 2 bytes (see below). Skip the entry.
return
}
// 大端存储
var kvLenBuf [4]byte
kvLenBuf[0] = byte(uint16(len(k)) >> 8)
kvLenBuf[1] = byte(len(k))
kvLenBuf[2] = byte(uint16(len(v)) >> 8)
kvLenBuf[3] = byte(len(v))
kvLen := uint64(len(kvLenBuf) + len(k) + len(v)) // 要写入的数据的长度
if kvLen >= chunkSize {
// Do not store too big keys and values, since they do not
// fit a chunk.
return
}
// chunk
// chunkIdx: chunk
// 0:[000000000000000000] // 64K
// 1:[000000000000000000]
// 2:[000000000000000000]
// 3:[000000000000000000]
chunks := b.chunks
needClean := false
b.mu.Lock()
idx := b.idx
idxNew := idx + kvLen
chunkIdx := idx / chunkSize
chunkIdxNew := idxNew / chunkSize
if chunkIdxNew > chunkIdx { //当前 chunk 放不下 该 kv, 往下一个 chunk 写 或者 循环写
if chunkIdxNew >= uint64(len(chunks)) { // 循环写
idx = 0
idxNew = kvLen
chunkIdx = 0
b.gen++ // 循环次数
if b.gen&((1<<genSizeBits)-1) == 0 { // b.gen&maxGen == 0, 说明 b.gen == maxGen
b.gen++ // 此处 ++ 的目的是为了 循环取余
}
needClean = true // 当 chunks 满了, 需要 从 头chunks[0]开始写, 需要把当前 chunk 全部清空.(清空 b.m)
} else { // 大部分场景
idx = chunkIdxNew * chunkSize
idxNew = idx + kvLen
chunkIdx = chunkIdxNew
}
chunks[chunkIdx] = chunks[chunkIdx][:0] // 将该chunk清空
}
chunk := chunks[chunkIdx]
// 首次初始化 , chunk[i] == nil
if chunk == nil {
chunk = getChunk() // 性能关键点: 堆外分配内存
chunk = chunk[:0]
}
// 正式写入数据
chunk = append(chunk, kvLenBuf[:]...)
chunk = append(chunk, k...)
chunk = append(chunk, v...)
chunks[chunkIdx] = chunk
b.m[h] = idx | (b.gen << bucketSizeBits) // gen + idx
b.idx = idxNew
if needClean {
// 清理 覆盖的 overflow 的 chunk(遍历 b.m,逐个 判断 清理)
b.cleanLocked()
}
b.mu.Unlock()
}gen: 循环次数, gen 在什么情况下 会 + 1?
bucket.gen 在初始化时默认值是 1, 当 chunks 写满后, gen 会 +1, 表示循环次数. 当 gen 达到 maxGen(1 << 24 -1) 后, gen 复位为1.
了解了 gen: 相信下面这几个条件就可以看懂了:
gen == bGen && idx < b.idx: 在一个循环内
gen+1 == bGen && idx >= b.idx: 不在一个循环内,数据没有覆盖
gen == maxGen && bGen == 1 && idx >= b.idx: 重新开始循环,数据没有覆盖
当 chunk 写满了, 使用下一个 chunk 时, 使用 getChunk() 初始化 chunk ?
getChunk() 在堆外分配内存, 而不是直接在堆上 分配, 减少GC压力. 这是 fastcache 高性能的一个关键点.
在 malloc_mmap.go 维护了一个 chunk 池子,可以复用 chunk.
const chunksPerAlloc = 1024
var (
//这里 相当于一个 chunk 池子
freeChunks []*[chunkSize]byte
freeChunksLock sync.Mutex
)
// 预分配 chunkSize*chunksPerAlloc 的 字节数组,(offheap), 通过 mmap
// 每次 getChunk 从中截取 chunkSize 大小的 []byte
func getChunk() []byte {
freeChunksLock.Lock()
// 如果 freechunk 没有了, 从堆外申请.
if len(freeChunks) == 0 {
// Allocate offheap memory, so GOGC won't take into account cache size.
// This should reduce free memory waste.
// 堆外申请内存, GOGC 不会考虑 缓存大小, 这应该会减少 free memory 浪费.
data, err := unix.Mmap(-1, 0, chunkSize*chunksPerAlloc, unix.PROT_READ|unix.PROT_WRITE, unix.MAP_ANON|unix.MAP_PRIVATE)
if err != nil {
panic(fmt.Errorf("cannot allocate %d bytes via mmap: %s", chunkSize*chunksPerAlloc, err))
}
for len(data) > 0 {
p := (*[chunkSize]byte)(unsafe.Pointer(&data[0]))
freeChunks = append(freeChunks, p)
data = data[chunkSize:]
}
}
n := len(freeChunks) - 1
p := freeChunks[n]
freeChunks[n] = nil
freeChunks = freeChunks[:n]
freeChunksLock.Unlock()
return p[:]
}3. Get
cache.Get()
// Get appends value by the key k to dst and returns the result.
//
// Get allocates new byte slice for the returned value if dst is nil.
//
// Get returns only values stored in c via Set.
//
// k contents may be modified after returning from Get.
func (c *Cache) Get(dst, k []byte) []byte {
h := xxhash.Sum64(k)
idx := h % bucketsCount // 这里 可以 优化为 位运算.
dst, _ = c.buckets[idx].Get(dst, k, h, true)
return dst
}
bucket.Get()
func (b *bucket) Get(dst, k []byte, h uint64, returnDst bool) ([]byte, bool) {
atomic.AddUint64(&b.getCalls, 1)
found := false
chunks := b.chunks
b.mu.RLock()
v := b.m[h] // 读取 value, 从中解析出 idx & gen
bGen := b.gen & ((1 << genSizeBits) - 1)
if v > 0 {
gen := v >> bucketSizeBits
idx := v & ((1 << bucketSizeBits) - 1)
// gen == bGen && idx < b.idx: 在一个循环内
// gen+1 == bGen && idx >= b.idx: 不在一个循环内,数据没有覆盖
// gen == maxGen && bGen == 1 && idx >= b.idx: 重新开始循环,数据没有覆盖
if gen == bGen && idx < b.idx || gen+1 == bGen && idx >= b.idx || gen == maxGen && bGen == 1 && idx >= b.idx {
chunkIdx := idx / chunkSize
if chunkIdx >= uint64(len(chunks)) {
// Corrupted data during the load from file. Just skip it.
// 文件加载时损坏的数据,跳过
atomic.AddUint64(&b.corruptions, 1)
goto end
}
chunk := chunks[chunkIdx]
idx %= chunkSize
if idx+4 >= chunkSize {
// Corrupted data during the load from file. Just skip it.
// 文件加载时损坏的数据,跳过
atomic.AddUint64(&b.corruptions, 1)
goto end
}
kvLenBuf := chunk[idx : idx+4]
keyLen := (uint64(kvLenBuf[0]) << 8) | uint64(kvLenBuf[1])
valLen := (uint64(kvLenBuf[2]) << 8) | uint64(kvLenBuf[3])
idx += 4
if idx+keyLen+valLen >= chunkSize {
// Corrupted data during the load from file. Just skip it.
// 文件加载时损坏的数据,跳过
atomic.AddUint64(&b.corruptions, 1)
goto end
}
// hash 值相同, 判断 key 是否一致
if string(k) == string(chunk[idx:idx+keyLen]) {
// dst = chunk[idx+keyLen:idx+valLen]
idx += keyLen
if returnDst {
dst = append(dst, chunk[idx:idx+valLen]...)
}
found = true
} else {
// 发生hash collision
atomic.AddUint64(&b.collisions, 1)
}
}
}
end:
b.mu.RUnlock()
if !found {
atomic.AddUint64(&b.misses, 1)
}
return dst, found
}
4. Del
del 的 逻辑比较简单. 不处理 chunk, 直接 在 bucket的hash表m中进行删除
func (b *bucket) Del(h uint64) {
b.mu.Lock()
delete(b.m, h)
b.mu.Unlock()
}
file Load | Save
file Save, 将缓存中的内容 按照一定的协议持久化写入文件中. 这个操作也比较常见.(比如 proto)
fileSave: 多携程 并发的写入 file, 多个协程 根据 bucket 分任务, 分别 写入文件,加速 写入 效率.
// SaveToFile atomically saves cache data to the given filePath using a single
// CPU core.
// 利用 但 cpu 保存 缓存数据到 filePath
//
// SaveToFile may be called concurrently with other operations on the cache.
//
// The saved data may be loaded with LoadFromFile*.
//
// See also SaveToFileConcurrent for faster saving to file.
func (c *Cache) SaveToFile(filePath string) error {
return c.SaveToFileConcurrent(filePath, 1)
}
// SaveToFileConcurrent saves cache data to the given filePath using concurrency
// CPU cores.
// 利用 多 cpu 将 缓存数据并发保存到文件.
// 这里参数的 filePath 也是一个 目录
//
// SaveToFileConcurrent may be called concurrently with other operations
// on the cache.
//
// The saved data may be loaded with LoadFromFile*.
//
// See also SaveToFile.
func (c *Cache) SaveToFileConcurrent(filePath string, concurrency int) error {
// Create dir if it doesn't exist.
dir := filepath.Dir(filePath)
if _, err := os.Stat(dir); err != nil {
if !os.IsNotExist(err) {
return fmt.Errorf("cannot stat %q: %s", dir, err)
}
if err := os.MkdirAll(dir, 0755); err != nil {
return fmt.Errorf("cannot create dir %q: %s", dir, err)
}
}
// Save cache data into a temporary directory.
tmpDir, err := ioutil.TempDir(dir, "fastcache.tmp.")
if err != nil {
return fmt.Errorf("cannot create temporary dir inside %q: %s", dir, err)
}
defer func() {
if tmpDir != "" {
_ = os.RemoveAll(tmpDir)
}
}()
gomaxprocs := runtime.GOMAXPROCS(-1)
if concurrency <= 0 || concurrency > gomaxprocs {
concurrency = gomaxprocs
}
// 并发保存数据到 文件
if err := c.save(tmpDir, concurrency); err != nil {
return fmt.Errorf("cannot save cache data to temporary dir %q: %s", tmpDir, err)
}
// Remove old filePath contents, since os.Rename may return
// error if filePath dir exists.
if err := os.RemoveAll(filePath); err != nil {
return fmt.Errorf("cannot remove old contents at %q: %s", filePath, err)
}
// 相当于 move
if err := os.Rename(tmpDir, filePath); err != nil {
return fmt.Errorf("cannot move temporary dir %q to %q: %s", tmpDir, filePath, err)
}
tmpDir = ""
return nil
}
保存数据到文件. 这也是一种常见的多协程 编程模式. 利用协程和 chan.
func (c *Cache) save(dir string, workersCount int) error {
if err := saveMetadata(c, dir); err != nil {
return err
}
// Save buckets by workersCount concurrent workers.
workCh := make(chan int, workersCount)
results := make(chan error)
for i := 0; i < workersCount; i++ {
go func(workerNum int) {
results <- saveBuckets(c.buckets[:], workCh, dir, workerNum)
}(i)
}
// 给 work 分发工作. 传 bucketIndex. workCh 相当于一个任务队列.
// Feed workers with work
for i := range c.buckets[:] {
workCh <- i
}
close(workCh)
// Read results. -- 如果使用 waitGroup 该怎么写呢?
var err error
for i := 0; i < workersCount; i++ {
result := <-results
if result != nil && err == nil {
err = result
}
}
return err
}
func saveBuckets(buckets []bucket, workCh <-chan int, dir string, workerNum int) error {
// 一个 协程 一个文件.
dataPath := fmt.Sprintf("%s/data.%d.bin", dir, workerNum)
dataFile, err := os.Create(dataPath)
if err != nil {
return fmt.Errorf("cannot create %q: %s", dataPath, err)
}
defer func() {
_ = dataFile.Close()
}()
// 数据进行压缩.
zw := snappy.NewBufferedWriter(dataFile)
for bucketNum := range workCh {
// save BucketNum
if err := writeUint64(zw, uint64(bucketNum)); err != nil {
return fmt.Errorf("cannot write bucketNum=%d to %q: %s", bucketNum, dataPath, err)
}
// save BucketData
if err := buckets[bucketNum].Save(zw); err != nil {
return fmt.Errorf("cannot save bucket[%d] to %q: %s", bucketNum, dataPath, err)
}
}
if err := zw.Close(); err != nil {
return fmt.Errorf("cannot close snappy.Writer for %q: %s", dataPath, err)
}
return nil
}
LoadFile:
[参考]
fastcache内部原理讲解及核心源码分析
golang本地缓存(bigcache/freecache/fastcache等)选型对比及原理总结